Microsoft’s new VALL-E “neural codec language model” can closely simulate a person’s voice when given just a three-second audio sample, and once it learns a specific voice, it can synthesise audio of that person saying anything, including with the right emotional tone. Pair VALL-E with another generative AI models such as GPT-3 and you have a content creation tool.
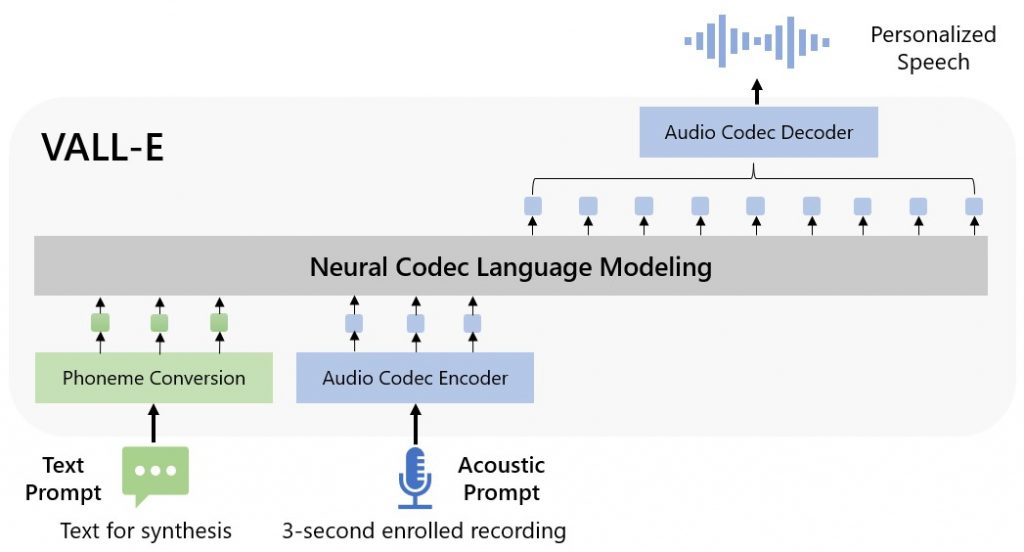
Rather than manipulating waveforms to synthesise speech, VALL-E generates discrete audio codec codes from text and acoustic prompts. It analyses how a person sounds, breaks that information into discrete components (called “tokens”) and uses training data from Meta’s LibriLight library to match what it “knows” about how that voice would sound if it spoke other phrases outside of the three-second sample.
For further information on how VALL-E works, see this Are Technica article.